Building a Frontend for a C-Like Compiler: My Journey
Introduction: Why Building a Frontend for a C-Like Compile
As a computer science student on the brink of graduation, I’ve always been fascinated by compilers and the inner workings of programming languages. A frontend is responsible for understanding the source code and transforming it into an intermediate representation (IR) that a backend can use for optimization or code generation. This project combines several fascinating concepts, from lexical analysis and parsing to symbol tables and abstract syntax trees(ASTs).I wanted to tackle all of these areas to solidify my understanding and develop something that could eventually integrate with a more robust backend, such as LLVM. In this post, I’ll walk you through my journey of building the frontend, the challenges I faced, the decisions I made, and the design patterns I used.
Step 1: Lexer – Tokenizing the Code
The first task in building a compiler is breaking down the source code into understandable chunks, and this is where the lexer comes in. A lexer, or tokenizer, converts the raw source code into a series of tokens, which are the basic building blocks of a programming language. For example, in the statement int x = 5;, the lexer would break it down into tokens like int, x, =, 5, and ;.
For my C-like language, I created a simple lexer that scans through the input code character by character. It recognizes various tokens, including:
- Keywords: int, float, if, else, while, etc.
- Identifiers: variable names like x, y, sum, etc.
- Literals: integer and floating-point numbers
- Operators: +, -, *, /, =, etc.
- Punctuation: ;, (, ), {, }, etc.
I implemented the lexer as a state machine that reads characters one by one and identifies patterns based on regular expressions. Once a pattern is matched, a corresponding token is generated and added to the token list.
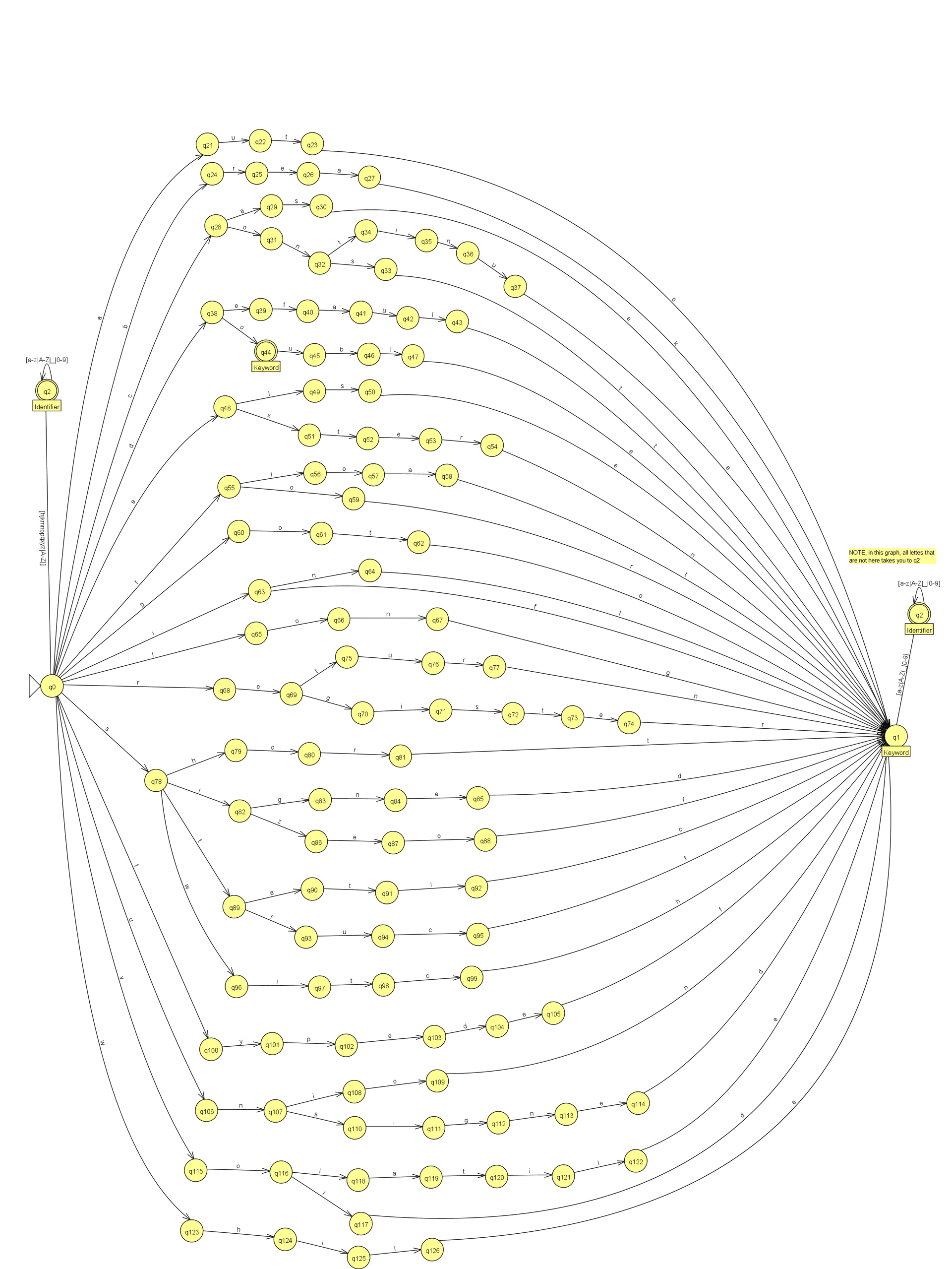
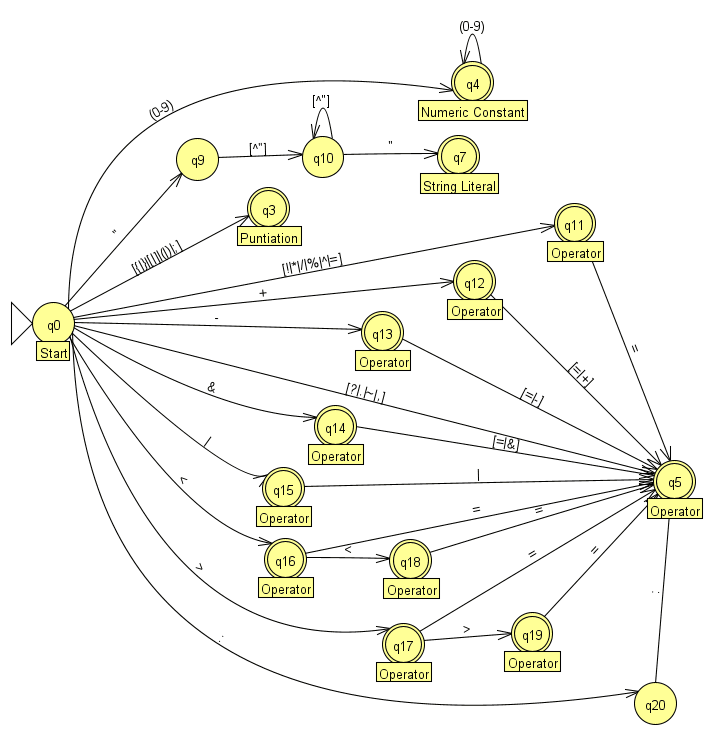
Initially, I implemented a table-driven lexer. In this approach, I created a set of tables that mapped input characters to corresponding states and actions (as shown in the image above). The lexer reads characters one by one and uses the tables to decide what token to generate. This table-driven method is a classic technique where you define a finite-state machine (FSM) to handle different parts of the language’s syntax. Each state represents a part of the token, and as characters are processed, the lexer transitions between states to recognize full tokens.
My implementation looks something this:
1
2void TableDrivenLexer::tokenize() {
3 char currentChar;
4 int currentState = 0; // Start state
5 int lastAcceptedState = -1; // Track the last valid (accepted) state
6 std::string lastAcceptedToken = ""; // Track the token at the last accepted state
7 std::streampos lastAcceptedPos; // Position in the stream for backtracking
8
9 TokenBuffer currentToken;
10
11 while (sourceCodeStream->get(currentChar)) {
12 if (currentState == 0 && std::isspace(currentChar)) { // Skip whitespace when in state 0
13 continue;
14 }
15
16 int nextState = automata.makeTransition(currentState, currentChar);
17
18 if (automata.isErrorState(nextState)) {
19 if (lastAcceptedState == -1) {
20 std::cerr << "Lexical Error: Unexpected character '" << currentChar << "' at state " << currentState << std::endl;
21 return;
22 }
23
24 TokenType tokenType = StateTypeToTokenType(automata.getStateType(lastAcceptedState));
25 tokens.push_back(Token(lastAcceptedToken, tokenType));
26
27 sourceCodeStream->clear();
28 sourceCodeStream->seekg(lastAcceptedPos);
29
30 currentToken.clear();
31 lastAcceptedToken.clear();
32
33 //reset state
34 currentState = 0;
35 lastAcceptedState = -1;
36
37 }
38 else {
39 currentToken.add(currentChar);
40 currentState = nextState;
41 lastAcceptedState = currentState;
42 lastAcceptedToken = currentToken.getString();
43 lastAcceptedPos = sourceCodeStream->tellg(); // Save stream position
44 }
45 }
46
47 if(lastAcceptedState == -1){
48 if( !currentToken.isEmpty()){
49 std::cerr << "Lexical Error: Unexpected end of input while processing token '" << currentToken.getString() << "'." << std::endl;
50
51 }
52 return;
53 }
54 //if ended without processing
55 TokenType tokenType = StateTypeToTokenType(automata.getStateType(lastAcceptedState));
56 tokens.push_back(Token(lastAcceptedToken, tokenType, lineNumber));
57}At first, I encoded all ANSI C keywords directly into the automata to recognize them during tokenization. However, as the project progressed, I realized that the complexity of working with the full ANSI C language. To simplify the implementation and improve flexibility, I decided to make a reduced version of C, focusing on a smaller subset of the language. This simplification made me reconsider the lexer’s design, and I opted to switch to Flex. Flex, a tool designed for generating lexers, allows you to describe regular expressions for tokens instead of manually encoding them into state tables. This shift to Flex provided more flexibility and made it much easier to manage changes to the lexer as the language evolved.
Step 2: Parser – Understanding the Syntax
A parser takes the sequence of tokens generated by the lexer and ensures they form valid statements according to the syntax of the programming language.
Designing the Parser with Context-Free Grammar
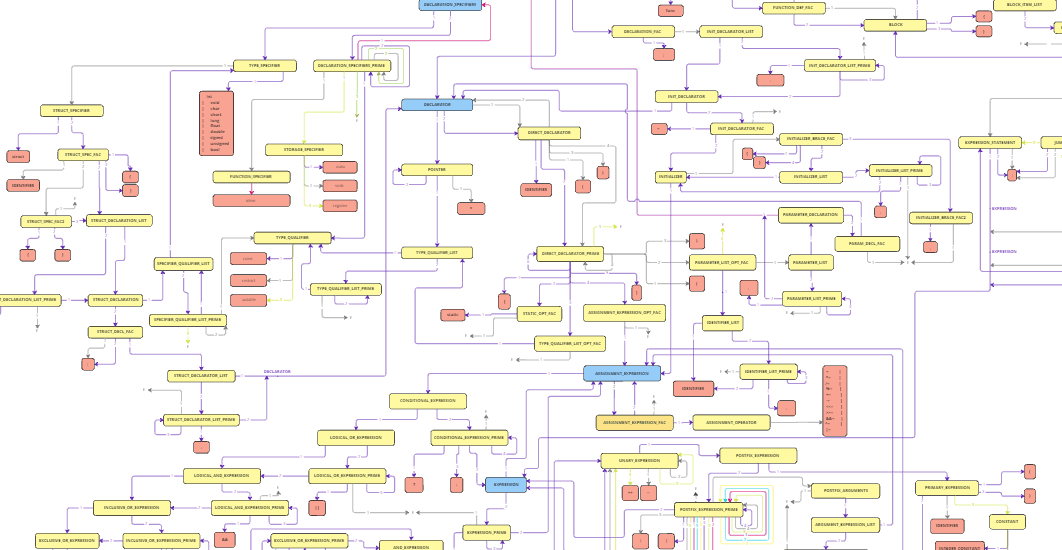
To define the structure of the language, I decided to use a Context-Free Grammar (CFG). A CFG is a formal grammar where each rule consists of a non-terminal symbol being replaced by a string of non-terminals and terminals (tokens). This formalism helps in describing the syntax of programming languages and allows the parser to check whether a sequence of tokens conforms to the grammar. The images below show the CFG, where every block represents a rule in the grammar and lines show how each of them relate.
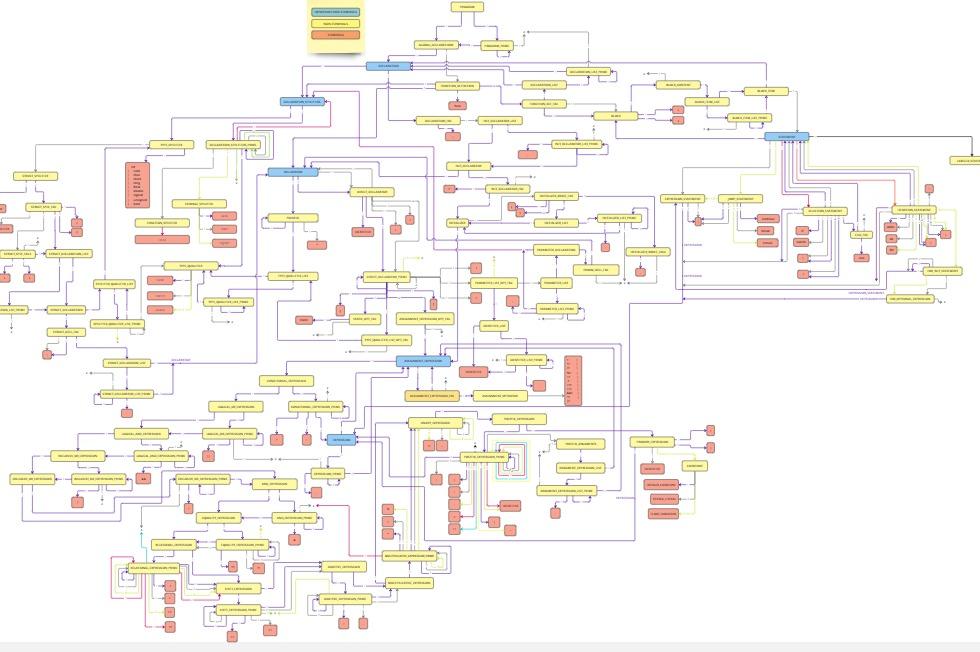
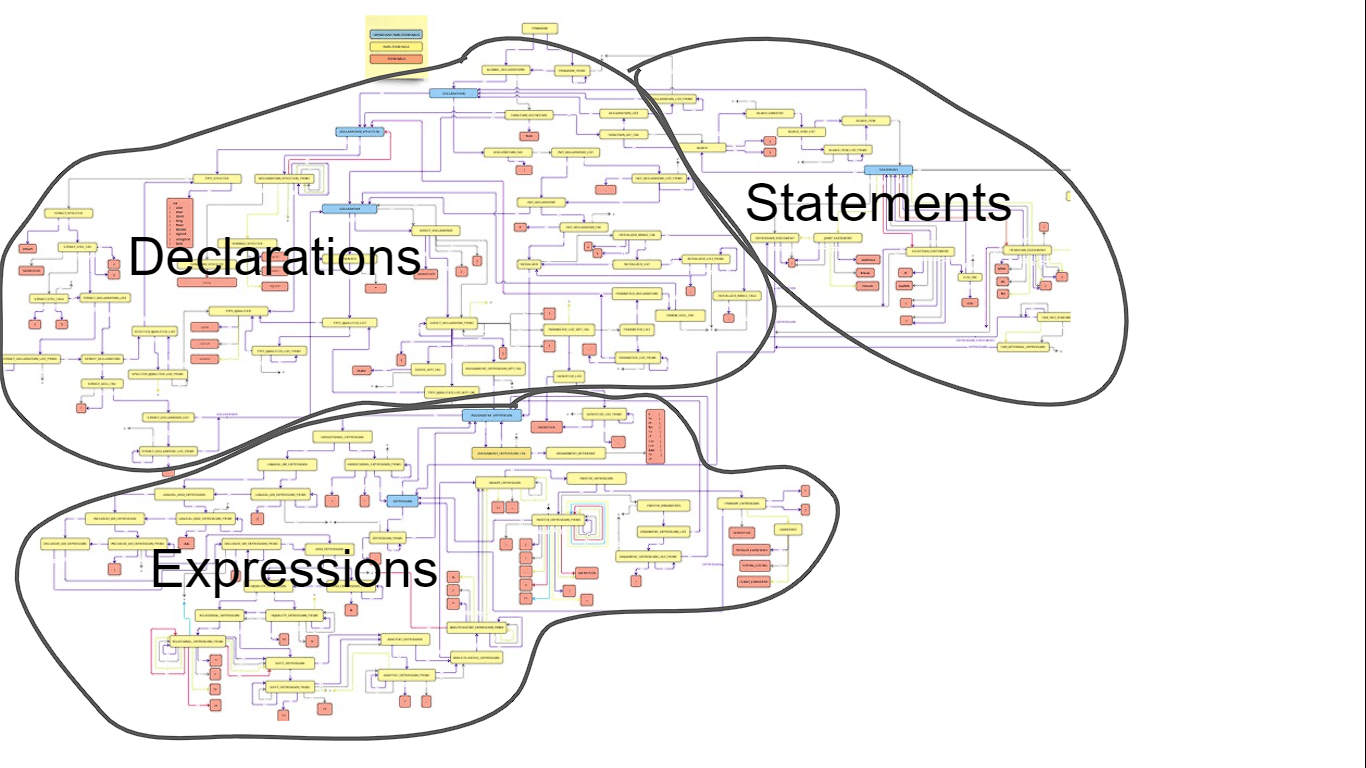
The first version of the grammar adhered strictly to the ANSI C standard, providing a comprehensive set of rules that reflected the full syntax of C. However, while this was accurate, it was more complex and posed challenges for parsing, especially when implementing a LL(1) parsing algorithm.
To adapt the grammar for LL(1) parsing, I created two more versions of the CFG. LL(1) parsers are a type of top-down parser that processes input left-to-right and uses a single lookahead token. However, LL(1) parsing has limitations—specifically, it struggles with left recursion (where a non-terminal can call itself) and ambiguity in certain grammar rules. Left factorization involved breaking down rules that could lead to ambiguity by factoring out common prefixes, ensuring the parser could make decisions with just a single lookahead token. These modifications resulted in a grammar that was simpler and more predictable for LL(1) parsing, but they also required me to reduce the language somewhat.
Some of the modifications i had to make were:
- All functions start with 'func' keyword, since in C, function and variable decalration can potentially start the same leading to ambiguity
- Eliminated the use of typedef, since it can lead to multiple ambiguity
- Eliminated posibility of multiple type qualifiers in a single declaration
For the parsing technique, I opted for recursive descent parsing, which is a straightforward and effective method for parsing context-free grammars. This technique involves writing a function for each non-terminal in the grammar, and each function recursively calls others to match the structure of the input tokens. Recursive descent parsing is particularly well-suited for languages with simple and deterministic grammars like the one I was designing.
1//...
2// Example of the first rules of my CFG implemented as a recursive descent parser
3// Note: This version show is without implementing AST
4// PROGRAM -> GLOBAL_DECLARATIONS PROGRAM_PRIME
5void Parser::parsePROGRAM()
6{
7 parseGLOBAL_DECLARATIONS(); //Recursive Descent Parsing here
8 parsePROGRAM_PRIME(); //Recursive Descent Parsing here
9
10 if (currentToken.getType() != TokenType::END_OF_FILE)
11 {
12 throw std::runtime_error("Unexpected token: " + currentToken.getValue());
13 }
14 return;
15}
16
17// PROGRAM_PRIME -> GLOBAL_DECLARATIONS PROGRAM_PRIME | ϵ
18void Parser::parsePROGRAM_PRIME()
19{
20 // Base Case: If the token is not in FIRST(PROGRAM_PRIME), return an empty ProgramPrimeAST for ε
21 if (!isDeclarationFirst())
22 {
23 return; // Return for ε
24 }
25
26 // Recursive Case: Parse a GLOBAL_DECLARATIONS node and recursively parse remaining PROGRAM_PRIME
27 parseGLOBAL_DECLARATIONS();
28
29 // Recursively parse the next PROGRAM_PRIME
30 parsePROGRAM_PRIME();
31}
32
33// GLOBAL_DECLARATIONS -> DECLARATION | FUNCTION_DEFINITION
34void Parser::parseGLOBAL_DECLARATIONS()
35{
36 if (currentToken.getType() == TokenType::KEYWORD && currentToken.getValue() == "func")
37 {
38 parseFUNCTION_DEFINITION();
39 return;
40 }
41
42 if (isBasicType())
43 {
44 parseDECLARATION();
45 return;
46 }
47 throw std::runtime_error("Unexpected token: " + currentToken.getValue());
48}
49//more rules below
50//...The parser then builds an intermediate representation, typically an Abstract Syntax Tree (AST), that reflects the structure of the code. . The AST acts as the internal representation of the program, which can later be analyzed and transformed into executable code or intermediate representations. To implement the AST, I used a hierarchical approach to create different types of nodes that represent various language constructs. Each node in the AST is a specialized instance of the ASTNode class, which serves as the base class for all AST nodes.
For example, a statement node is a subclass of ASTNode, and at the same time, the statement node might be one of the following types:
- Labled Statement: switch, case, default
- Expression Statement: Assignment, Function Call, Unary/Binary Operations, etc
- Iteration Statement: while, for, do-while
- Jump Statement: return, break, continue
- Block Statement: {}
Example of how the ASTNode implementation looks like:
1
2class ASTNode
3{
4public:
5 ASTNode(int line) : line_(line) {}
6 int getLine() const { return line_; }
7
8protected:
9 int line_;
10};
11
12class Stmt : public ASTNode
13{
14public:
15 Stmt(int line) : ASTNode(line) {}
16};
17}
18
19class LabaledStatement : public Stmt
20{
21public:
22 LabaledStatement(int line) : Stmt(line) {}
23 virtual ~LabaledStatement() = default;
24};
25
26class CaseStatement : public LabaledStatement
27{
28public:
29 CaseStatement(std::unique_ptr<Expr> expr, std::unique_ptr<Stmt> statement, int line)
30 : expr_(std::move(expr)), statement_(std::move(statement)), LabaledStatement(line) {}
31
32 Expr *getExpr() const { return expr_.get(); }
33 Stmt *getStatement() const { return statement_.get(); }
34
35private:
36 std::unique_ptr<Expr> expr_;
37 std::unique_ptr<Stmt> statement_;
38};
39
40//More nodes defined below, one for each language construct.
41//...Throughout the parsing process, each grammar rule not only consumes tokens but also constructs a part of the AST, and the parser recursively integrates these nodes into the tree. The recursive descent parser works hand-in-hand with the AST, enabling a clear representation of the program’s logic. Combining them looks as follows:
1
2// PROGRAM -> GLOBAL_DECLARATIONS PROGRAM_PRIME
3std::unique_ptr<Program> Parser::parsePROGRAM()
4{
5 std::vector<std::unique_ptr<ASTNode>> topLevelDeclarations;
6 topLevelDeclarations.push_back(parseGlobalDeclarations());
7
8 // PROGRAM_PRIME -> GLOBAL_DECLARATIONS PROGRAM_PRIME | ϵ
9 while (isDeclarationFirst())
10 {
11 topLevelDeclarations.push_back(parseGlobalDeclarations());
12 }
13
14 if (currentToken.getType() != TokenType::END_OF_FILE)
15 {
16 throw SyntacticException(currentToken.getLineNumber(), "Unexpected token: " + currentToken.getValue());
17 }
18 //here Program is type ASTNode
19 std::unique_ptr<Program> program = std::make_unique<Program>(std::move(topLevelDeclarations), currentToken.getLineNumber());
20
21 return program;
22}
23
24// GLOBAL_DECLARATIONS -> DECLARATION | FUNCTION_DEFINITION
25std::unique_ptr<ASTNode> Parser::parseGlobalDeclarations()
26{
27 if (currentToken.getType() == TokenType::FUNC)
28 {
29 //FunctionDecl is type ASTNode
30 std::unique_ptr<FunctionDecl> functionDecl = parseFunctionDefinition();
31 return functionDecl;
32 }
33 else if (isBasicType())
34 {
35 //Declaration is type ASTNode
36 std::unique_ptr<Declaration> declaration = parseDeclaration();
37 return declaration;
38 }
39 else
40 {
41 throw SyntacticException(currentToken.getLineNumber(), "Expected declaration or function definition");
42 }
43}
44After the Abstract Syntax Tree (AST) is constructed by the recursive descent parser, the next challenge is efficiently traversing the tree to perform various operations, such as semantic analysis. I used the Visitor Pattern, a behavioral design pattern that decouples the algorithm from the object structure. Instead of writing traversal logic directly into the AST node classes, I implemented the Visitor Pattern to allow various operations to be performed on the AST while keeping the node structure independent. For example:
1
2class ASTVisitor
3{
4public:
5 virtual ~ASTVisitor() = default;
6
7 // Visitor methods for each concrete AST node type
8 virtual void visit(Program &node) = 0;
9 virtual void visit(BinaryExpr &node) = 0;
10 virtual void visit(FunctionDecl &node) = 0;
11 virtual void visit(Declaration &node) = 0;
12 //other nodes ...
13};
14
15class ASTNode
16{
17public:
18 ASTNode(int line) : line_(line) {}
19 virtual void accept(ASTVisitor &visitor) = 0; //added this to all virtual nodes
20 int getLine() const { return line_; }
21
22protected:
23 int line_;
24};
25
26class Stmt : public ASTNode
27{
28public:
29 Stmt(int line) : ASTNode(line) {}
30 virtual void accept(ASTVisitor &visitor) = 0;
31};
32}
33
34class LabaledStatement : public Stmt
35{
36public:
37 LabaledStatement(int line) : Stmt(line) {}
38 virtual ~LabaledStatement() = default;
39 virtual void accept(ASTVisitor &visitor) = 0;
40};
41
42class CaseStatement : public LabaledStatement
43{
44public:
45 CaseStatement(std::unique_ptr<Expr> expr, std::unique_ptr<Stmt> statement, int line)
46 : expr_(std::move(expr)), statement_(std::move(statement)), LabaledStatement(line) {}
47
48 //added this method to all concrete nodes
49 void accept(ASTVisitor &visitor) override
50 {
51 visitor.visit(*this);
52 }
53
54 Expr *getExpr() const { return expr_.get(); }
55 Stmt *getStatement() const { return statement_.get(); }
56
57private:
58 std::unique_ptr<Expr> expr_;
59 std::unique_ptr<Stmt> statement_;
60};
61
62//More nodes defined below, one for each language construct.
63//...Step 3: Symbol Table – Managing Variables, Functions, and Scopes
A crucial component of any compiler is the symbol table, which manages the symbols used in the program, such as variables, functions, and their corresponding scopes. In my implementation, I opted for a hash-based symbol table with chained scopes to efficiently track these symbols across different levels of the program.
The main challenge I faced during this phase was managing the scopes of the program. In a language with nested blocks, such as functions, loops, and conditionals, variables and functions can be declared and accessed in different levels of scope. To resolve this, I implemented a hash-based symbol table with chained scopes. Each scope in the symbol table contains a hash map of symbol names to their corresponding metadata. The scopes are linked in a chain, where each scope has a reference to its parent scope. The structure of the Symbol Table looks like this:
1class SymbolTable : public std::enable_shared_from_this<SymbolTable>
2{
3private:
4 std::unordered_map<std::string, std::shared_ptr<Symbol>> symbols;
5 std::shared_ptr<SymbolTable> parent;
6
7public:
8 explicit SymbolTable(std::shared_ptr<SymbolTable> parent = nullptr);
9 bool insertSymbol(std::shared_ptr<Symbol> symbol);
10 std::shared_ptr<Symbol> lookupSymbol(const std::string &name) const;
11 std::shared_ptr<SymbolTable> createChildScope();
12 std::shared_ptr<SymbolTable> getParent() const;
13 std::shared_ptr<FunctionSymbol> getFunctionSymbol() const;
14 void printCurrentScope() const;
15};To manage the different types of symbols in my language, I created a base class called Symbol. From this base class, I derived specific classes for each type of symbol. For instance, I have a VariableSymbol class for variables, a FunctionSymbol class that stores the function signature, and a StructSymbol class. Both the FunctionSymbol and StructSymbol classes can also store lists of variable symbols inside them.
To implement the semantic analyzer, I leveraged the Visitor pattern that I had created earlier. I also implemented methods to compare types, which made it easier to check the consistency of the code during analysis. The semantic analysis process was particularly challenging, as it required handling a wide variety of cases. Unlike simple tasks like checking if left and right values have the same type or if a symbol exists and has the correct type in the symbol table, the analysis often involved more complex logic depending on the context.
1class SemanticAnalyzer : public ASTVisitor
2{
3private:
4 std::shared_ptr<SymbolTable> symbolTable;
5 std::shared_ptr<SemanticType> inferredType;
6};
7public:
8 explicit SemanticAnalyzer(std::shared_ptr<SymbolTable> symbolTable) : symbolTable(std::move(symbolTable)) {}
9
10 void acceptIfNotNull(ASTNode *node)
11 {
12 if (node != nullptr)
13 {
14 node->accept(*this);
15 }
16 }
17
18 void acceptIfNotNull(const std::unique_ptr<ASTNode> &node)
19 {
20 acceptIfNotNull(node.get());
21 }
22
23 template <typename NodeType>
24 void acceptIfNotNull(const std::unique_ptr<NodeType> &node)
25 {
26 acceptIfNotNull(node.get());
27 }
28
29 void visit(Program &node) override
30 {
31 for (const auto &decl : node.getTopLevelDeclarations())
32 {
33 acceptIfNotNull(decl);
34 }
35 }
36
37 void visit(BinaryExpr &node) override
38 {
39 acceptIfNotNull(node.getLHS());
40 auto lhsType = inferredType; //this saves the type the left node had
41
42 acceptIfNotNull(node.getRHS());
43 auto rhsType = inferredType; //this saves the type the right node had
44
45 if (!lhsType || !rhsType)
46 {
47 throw SemanticException(node.getLine(), "Both operands of binary expression must have valid types.");
48 }
49
50 // Operator-dependent type inference
51 if (node.getOp() == "+" || node.getOp() == "-" || node.getOp() == "*" || node.getOp() == "/")
52 {
53 if ((lhsType->equals(PrimitiveSemanticType(DataType::INT)) || lhsType->equals(PrimitiveSemanticType(DataType::FLOAT)) ||
54 lhsType->equals(PrimitiveSemanticType(DataType::DOUBLE))) &&
55 (rhsType->equals(PrimitiveSemanticType(DataType::INT)) || rhsType->equals(PrimitiveSemanticType(DataType::FLOAT)) ||
56 rhsType->equals(PrimitiveSemanticType(DataType::DOUBLE))))
57 {
58 // The result will be the type that can hold the largest value
59 if (lhsType->equals(PrimitiveSemanticType(DataType::DOUBLE)) || rhsType->equals(PrimitiveSemanticType(DataType::DOUBLE)))
60 {
61 inferredType = std::make_shared<PrimitiveSemanticType>(DataType::DOUBLE);
62 }
63 else if (lhsType->equals(PrimitiveSemanticType(DataType::FLOAT)) || rhsType->equals(PrimitiveSemanticType(DataType::FLOAT)))
64 {
65 inferredType = std::make_shared<PrimitiveSemanticType>(DataType::FLOAT);
66 }
67 else
68 {
69 inferredType = std::make_shared<PrimitiveSemanticType>(DataType::INT);
70 }
71 }
72 else
73 {
74 throw SemanticException(node.getLine(), "Operands must be numeric for binary arithmetic operation.");
75 }
76 }
77 else if (node.getOp() == "==" || node.getOp() == "!=" || node.getOp() == "<" || node.getOp() == ">" ||
78 node.getOp() == "<=" || node.getOp() == ">=")
79 {
80 if ((lhsType->equals(PrimitiveSemanticType(DataType::INT)) || lhsType->equals(PrimitiveSemanticType(DataType::FLOAT)) ||
81 lhsType->equals(PrimitiveSemanticType(DataType::DOUBLE)) || lhsType->equals(PrimitiveSemanticType(DataType::CHAR))) &&
82 (rhsType->equals(PrimitiveSemanticType(DataType::INT)) || rhsType->equals(PrimitiveSemanticType(DataType::FLOAT)) ||
83 rhsType->equals(PrimitiveSemanticType(DataType::DOUBLE)) || rhsType->equals(PrimitiveSemanticType(DataType::CHAR))))
84 {
85
86 // The result will be boolean
87 inferredType = std::make_shared<PrimitiveSemanticType>(DataType::BOOL);
88 }
89 else
90 {
91 throw SemanticException(node.getLine(), "Operands must be comparable for binary comparison operation.");
92 }
93 }
94 else if (node.getOp() == "&&" || node.getOp() == "||")
95 {
96 // Logical operators: both operands must be boolean
97 if (lhsType->equals(PrimitiveSemanticType(DataType::BOOL)) && rhsType->equals(PrimitiveSemanticType(DataType::BOOL)))
98 {
99 inferredType = std::make_shared<PrimitiveSemanticType>(DataType::BOOL);
100 }
101 else
102 {
103 throw SemanticException(node.getLine(), "Operands must be boolean for binary logical operation.");
104 }
105 }
106 else
107 {
108 throw SemanticException(node.getLine(), "Unsupported operator for binary expression.");
109 }
110 }
111
112 //Implement all ASTVisitor methods for each concrete node type
113 //...
114};
115Result
While the language is a simplified version of C, it supports essential features such as variable declarations, function definitions, and various types of statements. Some of the features I implemented include:
Variables Out of Scope
1// code snippet of my language
2func int calculate_sum(int a, int b) {
3 return a + b;
4}
5
6func int main() {
7 int x = 5;
8 {
9 int y = 10;
10 int result = calculate_sum(x, y); // Valid
11 }
12 int result = calculate_sum(x, y); // Error: 'y' is out of scope
13 return 0;
14}Type Checking in Assignments
1// code snippet of my language
2func int double_value(int a) {
3 return 2 * a;
4}
5
6func int main() {
7 1 = 10; // Error: Cannot assign to a constant Lvalue
8
9 char str[10] = "hello";
10 int doubled = double_value(str); // Error: Implicit type conversion from 'char[]' to 'int'
11 return 0;
12}Data Type Compatibility in Expressions
1// code snippet of my language
2func int main() {
3 int a = 5;
4 a = (1>3) + 4; // bool + int
5 return 0;
6}Return Type Consistency
1// code snippet of my language
2func int square(int n) {
3 return n * n;
4}
5
6func void print_value(int n) {
7 return n; // Error: Return type 'void' cannot return a value
8}
9
10func int main() {
11 int result = square(4); // Valid
12 return 0;
13}Function Signature Matching
1// code snippet of my language
2func int multiply(int a, int b) {
3 return a * b;
4}
5
6func int main() {
7 int product = multiply(3, 4); // Valid
8 product = multiply(3); // Error: Incorrect number of arguments
9 product = multiply(2, "hi"); // Error: Incorrect Type
10 return 0;
11}Struct Member Access
1// code snippet of my language
2struct Point {
3 int x;
4 int y;
5};
6
7func int calculate_distance(struct Point p) {
8 return p.x * p.x + p.y * p.y;
9}
10
11func int main() {
12 struct Point p;
13 p.x=3;
14 p.y=4;
15 int distance = calculate_distance(p); // Valid
16 int error = p.z; // Error: 'z' is not a member of 'Point'
17 return 0;
18}Pointer Arrow (->) Operator Usage
1// code snippet of my language
2struct Node {
3 int data;
4 struct Node *next;
5};
6
7func int get_data(struct Node *node) {
8 return node->data;
9}
10
11func int main() {
12 struct Node *ptr;
13 int value = get_data(ptr); // Valid
14 return 0;
15}Break and Continue Statement Validation
1// code snippet of my language
2func void loop_example() {
3 while (1) {
4 break; // Valid
5 }
6}
7
8func int main() {
9 if (1) {
10 break; // Error: 'break' outside of a loop or switch
11 }
12 loop_example();
13 return 0;
14}Array Initialization with Brace {} Matching Dimensions
1// code snippet of my language
2func int main() {
3 int arr[3] = {1, 2, 3}; // Valid
4 return 0;
5}Constant Types in Case Statements
1// code snippet of my language
2func int get_status(int value) {
3 switch (value) {
4 case 1: // Valid
5 return 0;
6 case value + 1: // Error: 'value + 1' is not a constant expression
7 return -1;
8 }
9 return 1;
10}
11
12func int main() {
13 int result = get_status(1);
14 return 0;
15}Working on this project taught me valuable lessons that extend beyond technical expertise. I developed a better understanding of how to structure code and make thoughtful design decisions. Breaking down complex tasks into manageable components helped me realize the importance of keeping code modular and maintainable. I also honed my problem-solving skills, learning to approach challenges from different angles and adapt when needed.